The NULL Trap: When WHERE <> Doesn't Do What You Think

Earlier this year, we had a bug that slipped through code review, made it to production, and took us a day to diagnose. The query was simple (a hypothetical example, the real query in our internal system is different):
SELECT * FROM message_threads WHERE assignee_id != user_1_id;
We wanted to get all threads not assigned to user_1. That should include threads assigned to user_2, user_3, user_4, and—critically—threads with no assignee at all (unassigned threads).
It didn’t. The unassigned threads were missing from the results.
The Assumption That Broke Us
We assumed != works like a boolean filter: “give me everything that’s not this value.” In most programming languages, that’s what != does. If you have [foo, bar, null] and filter by != 'bar', you get [foo, null].
Not in SQL.
Postgres (and standard SQL) uses three-valued logic: TRUE, FALSE, and UNKNOWN. Any comparison with NULL yields UNKNOWN, not TRUE or FALSE. When you write:
WHERE column != 'bar'
Postgres evaluates each row:
'foo' != 'bar'→ TRUE (included)'bar' != 'bar'→ FALSE (excluded)NULL != 'bar'→ UNKNOWN (excluded)
UNKNOWN is treated as FALSE in WHERE clauses. So NULLs are always filtered out when using !=, =, <, >, or any standard comparison operator.
Our query WHERE assignee_id != user_1_id was returning only threads with a non-null assignee that wasn’t user_1. All unassigned threads (where assignee_id IS NULL) disappeared.
The Real Impact
In our real system (not the hypothetical example on top), it was a query that validates against ticket duplication. The query was allowing all duplicates because certain tickets were missing a relation (by design) thus, each time the user scans the ticket, it will not be considered a duplicate at first then the system behaves differently.
The fix wasn’t just “add OR assignee_id IS NULL“—it was understanding that our mental model of inequality was wrong for Postgres.
How to Actually Get “Not This Value” Including NULLs
Postgres gives you a few correct ways to express “not equal, treating NULL as a distinct value.”
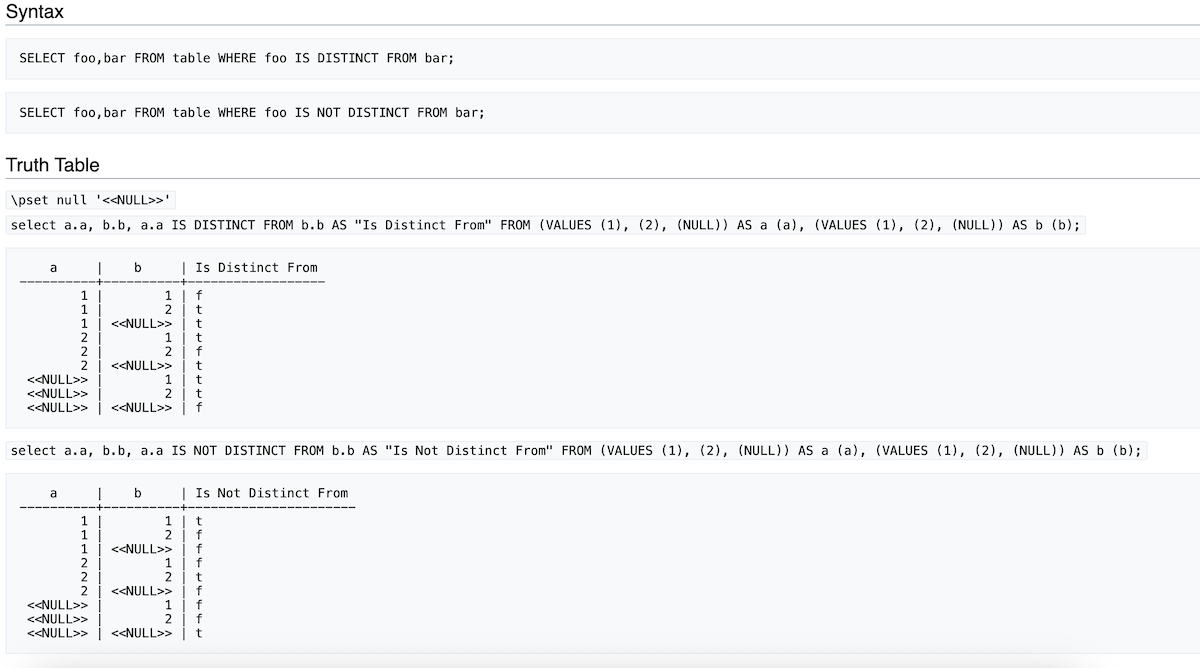
Option 1: IS DISTINCT FROM
SELECT * FROM message_threads WHERE assignee_id IS DISTINCT FROM user_1_id;
This is the NULL-safe inequality operator. It returns TRUE for:
- Any value that is not user_1_id
- NULL values (because NULL IS DISTINCT FROM user_1_id is TRUE)
It returns FALSE only when the value is exactly user_1_id.
Option 2: Explicit NULL handling
SELECT * FROM message_threads WHERE assignee_id != user_1_id OR assignee_id IS NULL;
This is what we initially patpped. It works, but it’s verbose and easy to forget the OR clause.
Performance and Edge Cases
IS DISTINCT FROM is the cleanest, but know these details:
- Index usage:
IS DISTINCT FROMcan use a b-tree index onassignee_id. Postgres can transform it into a range scan. The same goes for the explicitOR assignee_id IS NULLpattern. - NULL vs NULL:
NULL IS DISTINCT FROM NULLreturns FALSE (they are not distinct; both are NULL). If you want NULLs to match each other, useIS NOT DISTINCT FROM(the NULL-safe equality). - Portability:
IS DISTINCT FROMis standard SQL and supported by Postgres, MySQL (as<=>for equality only), and others. Check your database’s support. - Readability:
IS DISTINCT FROMreads clearly once you know it exists. The explicitORpattern is more universally understood but more verbose.
Conclusion
The bug wasn’t about knowing IS DISTINCT FROM. It was about questioning your thinking model.
We wrote != user_1_id assuming it meant “not user_1.” In SQL, it means “not user_1 and not unknown.” That subtle difference is why NULLs disappeared. After this incident, we audit all inequality queries on nullable columns. We ask: “Do we want NULLs here?” If yes, we use IS DISTINCT FROM or add the explicit null check.
More broadly: when a query returns fewer rows than expected, check your NULL logic. A missing IS NULL clause is a common source of silent data loss.